On the Robustness of Vision Transformers to Adversarial Examples(ICCV2021)
代码链接:https://github.com/MetaMain/ViTRobust
本文研究了ViT鲁棒性,迁移安全性研究分为3点:
- 在白盒和黑盒攻击场景下测试 transformer 鲁棒性
- 对抗样本很难从 CNN 迁移到 transformer,基于这一发现分析 CNN 和 transformer 简单的集成防御的安全性。
- 提出一种 self-attention blended gradient attack(SAGA),简单集成防御模型对于白盒攻击时不安全的,在黑盒对抗攻击下,作者指出集成防御模型可以在不牺牲准确率的情况下,达到较好的鲁棒性。
Vision Transformer白盒攻击
攻击方法:测试6种不同的白盒攻击方法:FGSM,MIN,PGD,APGD(Auto Projected Gradient Descent[1]),C&W,当梯度masking或者梯度混淆出现时白盒攻击失败,Backward Pass Differentiable Approximation (BPDA)[2],解决上述问题。
分类模型:ViT-B-32,ViT-B-16,ViT-L-16,ViT-R50,B代表模型复杂度,B模型有12层,L模型有24层。Big Transfer Models:BiT-M-R50 和 BiT-M-R101x3,ResNet-56 和ResNet-164,对于CIFAR-10 和 CIFAR-100,攻击8个模型,ViT-B-32,ViT-B-16,ViT-L-16,ViT-R50,BiT-M-R50,BiT-M-R101x3,ResNet-56 和 ResNet-164,对于ImageNet,攻击7个模型:ViT-B-16,ViT-L-16(图片大小224),ViT-L-16 (图片大小512),BiT-M-R50,BiT-MR152x4,ResNet-50 和 ResNet-152。
实验结果:
表一
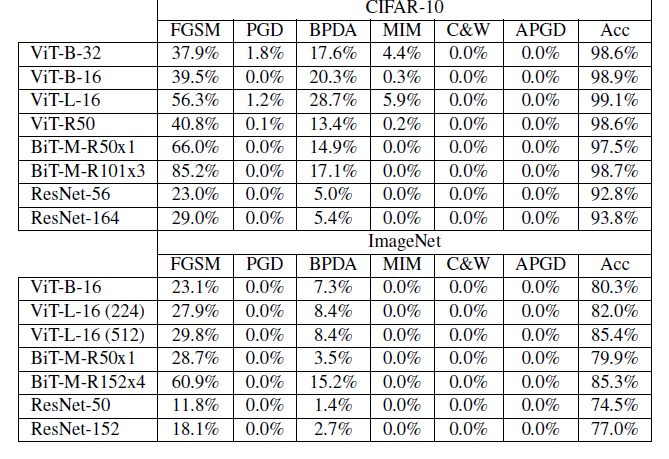
ViT对白盒攻击没有鲁棒性,表中数值代表对抗样本分类准确率,Acc代表这个模型干净样本准确率。
ViT迁移性研究
表二
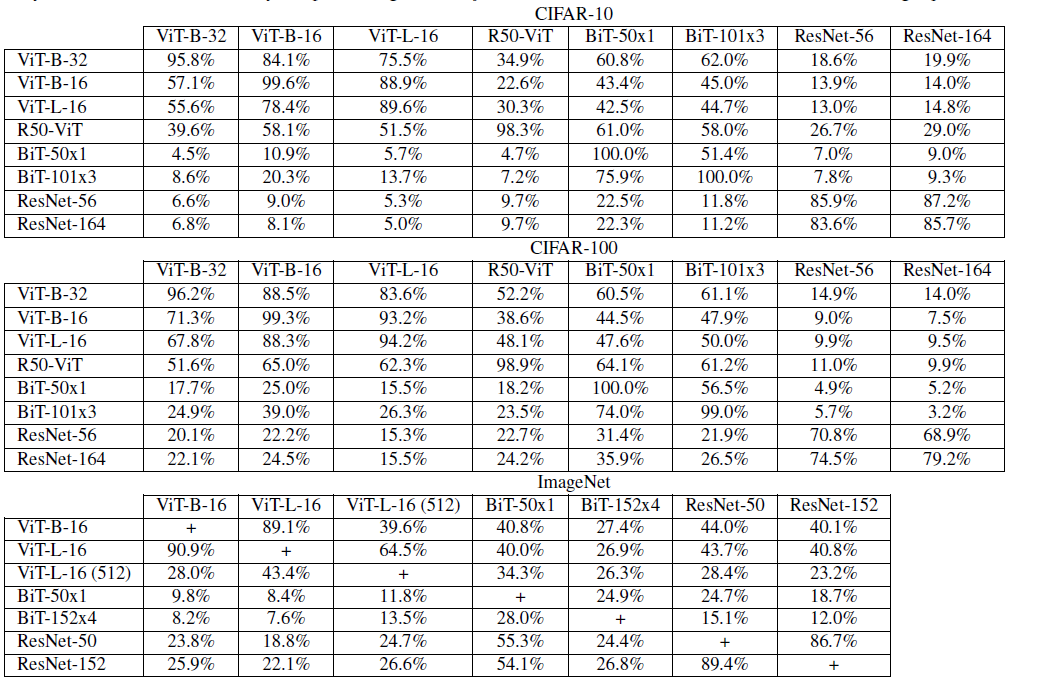
表中每个数据取几种攻击方法最高迁移率。
SAGA
原文:
Instead of focusing completely on optimizing over one of the models, SAGA focuses on breaking multiple models at once.
攻击目标:Vision Transformers集合\(V\),CNN集合\(K\),在扰动\(\epsilon\)边界条件下使\(V\)和\(K\)所有成员都错分。 \[ x_{a d v}^{(i+1)}=x_{a d v}^{(i)}+\epsilon_{s} * \operatorname{sign}\left(G_{b l e n d}\left(x_{a d v}^{(i)}\right)\right) \]
\[ G_{b l e n d}\left(x_{a d v}^{(i)}\right)=\sum_{k \in K} \alpha_{k} \frac{\partial L_{k}}{\partial x_{a d v}^{(i)}}+\sum_{v \in V} \alpha_{v} \phi_{v} \odot \frac{\partial L_{v}}{\partial x_{a d v}^{(i)}} \]
\(\phi_{v}\) 是\(v^{th}\) transformer 的自注意力图,用 attention rollout [3]计算如下 \[ \phi_{v}=\left(\prod_{l=1}^{n_{l}}\left[\sum_{i=1}^{n_{h}}\left(0.5 W_{l, i}^{(a t t)}+0.5 I\right)\right]\right) \] \(n_h\) 是每层attention heads个数,\(n_l\) 是注意力层数,\(W_{l,i}^{(att)}\)是每个attention heads注意力权重矩阵,\(I\)是恒等矩阵,\(x\)是输入图像,这个公式考虑到注意力从transformer 每一层流动到下一层,包括跳跃链接的影响。平均来自同一层内不同attention heads的注意力值,注意力值在不同层之间递归地相乘。
实验结果:
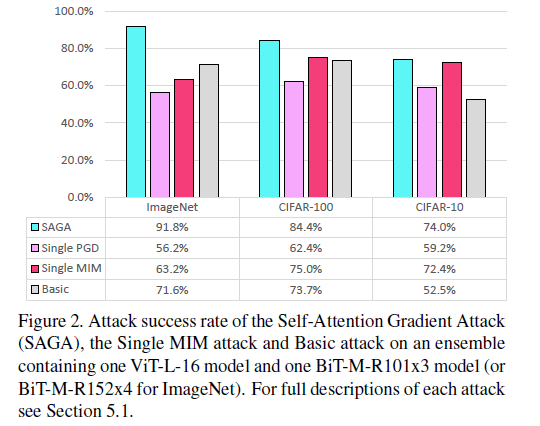
对Vision Transformers 和 Big Transfer Models简单集成的攻击,使用1000张正确分类的图片,
basic attack 是没有权重参数和自注意力的梯度的组合,SAGA攻击的贡献在于证明了Vision Transformers 和 Big Transfer Models简单集成对于白盒攻击是不安全的。SAGA攻击优于其他两种攻击。
黑盒安全性和迁移性
测试了 RayS attack[4] 和 Adaptive Black-Box Attack[5] 的安全性,最大查询次数10000,对于 Adaptive Black-Box Attack,攻击者可以获得全部训练数据,synthetic model 为 ViTB-32。Vision Transformer 和 Big Transfer model 的简单集成大幅提高了安全性。
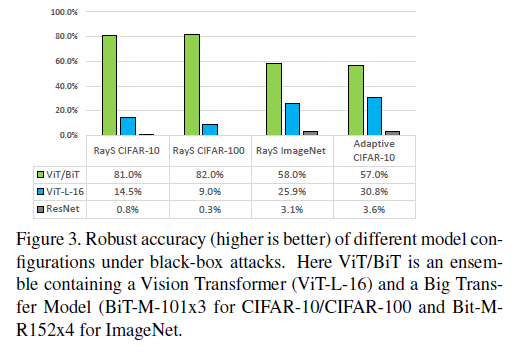
[1] Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In International Conference on Machine Learning, pages 2206–2216. PMLR, 2020.
[2] Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In Proceedings of the 35th International Conference on Machine Learning, pages 274– 283, 2018.
[3] Samira Abnar and Willem Zuidema. Quantifying attention flow in transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4190–4197, 2020.
[4] Jinghui Chen and Quanquan Gu. Rays: A ray searching method for hard-label adversarial attack. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1739–1747, 2020.
[5] Kaleel Mahmood, Phuong Ha Nguyen, Lam M. Nguyen, Thanh Nguyen, and Marten van Dijk. Buzz: Buffer zones for defending adversarial examples in image classification, 2020.