Practical No-box Adversarial Attacks against DNNs
发表在 NeurIPS 2020,代码:https://github.com/qizhangli/nobox-attacks
提出 no box 设定:禁止查询目标模型,模型结构参数和训练数据也未知,攻击者只能收集来自相似任务的少量数据(几十张或者更少)。依靠这些少量的数据进行有监督的训练得到一个替代模型十分困难。
本文使用 auto-encoders 从少量数据(来自两个类别的20张图片)学习判别性的特征,并研究了三种训练机制:a) 估计每个旋转图像的正面视图,b) 估计每个可能的拼图的最佳拟合,c) 构建原型图像。auto-encoding 模型生成的对抗样本可以很好的迁移到不同的目标模型上,它的有效性有时与使用在与目标模型相同的大规模数据集上训练的预训练模型构建的样本不相上下。
方法
训练方法
本文针对非目标攻击,训练集 \(\mathcal{X}:=\{(x_i,y_i)\}_{i=0}^{n-1}\) ,本文考虑这个辅助数据集一共有两类,i.e.,\(y_i\in \{0,1\}\)。
Baseline 借助于图像到图像的映射,它们在建模数据的内部分布方面是成功的,最小化\(\sum_i \Vert\text{Dec}(\text{Enc}(x_i))-x_i \Vert^2\), 这样的模型一方面能够捕获低层次的图像表示,不会遭受严重的过拟合,另一方面,模型没有判别能力,因此针对模型生成的对样本例很难迁移到其他模型上。
Reconstruction from chaos 已有研究表明,预测图像旋转角度和拼图构型赋予DNNs相当大的判别能力,使用image-to-image auto-encoding 模型,结合上述辅助信息,引入评估任务:(a) 每个旋转图像的前视图和 (b) 每一个可能的拼图的完美配合,学习目标函数: \[ L_{\text{rotaion/jigsaw}}=\frac{1}{n}\sum_{i=0}^{n-1}\Vert \text{Dec}(\text{Enc}(T(x_i)))-x_i\Vert^2 \]
上式图像转换函数\(T(\cdot)\) 对于这两个任务分别是旋转图像和随机打乱图像patches,虽然学习任务仍然像经典的自动编码器一样是无监督,但辅助信息是与内容相关的,应该有利于分类。
Prototypical image reconstruction 利用标签信息,鼓励模型重建特定类别原型, \[ L_{\text {prototypical}}=\frac{1}{n} \sum_{i=0}^{n-1}\left(\left(1-y_i\right)\left\|\text{Dec}\left(\text{Enc}\left(x_i\right)\right)- x^{(0)}\right\|^2+y_i\left\|\text{Dec}\left(\text{Enc}\left(x_i\right)\right)-x^{(1)}\right\|^2\right) \] 上式\(x^0 \in \{x_i|y_i=0\}\),\(x^1 \in \{x_i|y_i=1\}\)是随机选择的类别原型,这种机制背后的直觉是,一个模型将必须区分具有不同标签的样本,以获得完美的训练
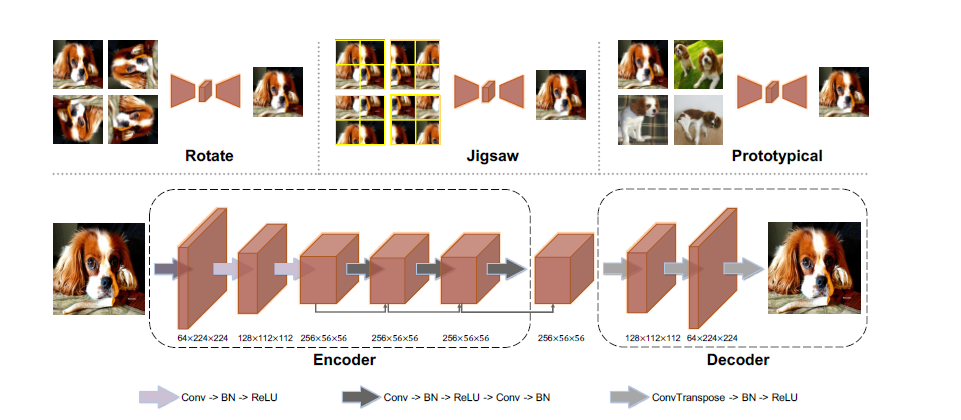
提高攻击迁移性
定义 auto-encoding 模型的对抗损失,这个损失用来训练模型,对每个\(x_i\) 重建 \(\tilde{x}_i\)。 \[ L_{\text {adversarial }}=-\log p\left(y_i \mid x_i\right) \quad \text { where } \quad p\left(y_i \mid x_i\right)=\frac{\exp \left(-\lambda\left\|\text{Dec}\left(\text{Enc}\left(x_i\right)\right)-\tilde{x}_i\right\|^2\right)}{\sum_j \exp \left(-\lambda\left\|\text{Dec}\left(\text{Enc}\left(x_i\right)\right)-\tilde{x}_j\right\|^2\right)} \] \(\lambda>0\),对于旋转和拼图,\(\tilde{x}_i:=x\),对于原型重建,当 \(x_i\) 的标签 \(y_i=0\),\(\tilde{x}_i:=x^{(0)}\)。这样的\(\tilde{x}_i\)被称为 \(x_i\) 的 positive prototype,通过攻击,他们的距离增大,对抗损失\(L_{\text{adversarial}}\)最大化。在本文中使用ILA攻击方法,首先使用一个基于梯度的攻击方法获得一个攻击扰动,然后用编码器的输出进行ILA攻击。
实验
设定 分类任务:从 ImageNet 随机选择5000张(500类,一类10张),\(\epsilon = 0.1\)或者\(0.8\)。人脸验证任务:LFW数据集,随机选取来自400个个体2110张图,\(\epsilon = 0.1\),攻击一个商用系统 clarifai.com。图片resize为\(112\times112\)。
方法 对于rotation,考虑四个选择角度:0°,90°,180°,270°,对于jigsaw,原始图形平均分为四部分随机打乱,优化器adam,学习率0.001,最大训练次数15000,一个替代模型训练完毕后,I-FGSM攻击200步,然后ILA 100步,\(\lambda = 1\),对于ImageNet和LFW,攻击步长1/255.
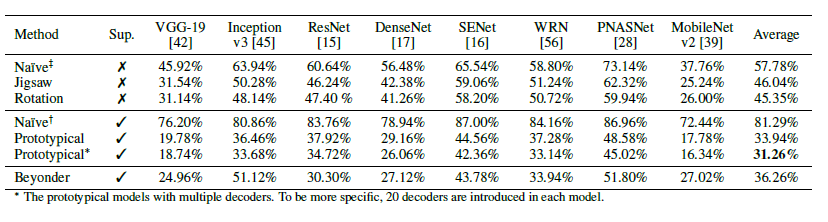
Competitors 本文提出两个baseline,\(naïve^{\dagger}\):监督训练的ResNets,正则化和数据增广训练得到,\(naïve^{\ddagger}\):无监督训练的 auto-encoders,\(naïve^{\dagger}\)和\(naïve^{\ddagger}\)训练数据不超过20张图像,\(Beyonder\):在大规模数据集预训练的模型,训练数据和目标模型一致,在本文中选取ResNet-50
实验结果 对于prototypical机制测试单个解码器和多个解码器的模型,无监督训练的模型rotation最优,
Adversarial Pixel Restoration as a Pretext Task for Transferable Perturbations
发表在 BMVC 2022,代码:https://github.com/HashmatShadab/APR
设定和上一篇相同,在上一篇工作中prototypical方法需要有监督训练,为了减小对少量样本数据的过拟合,并且找到鲁棒的特征,提出对抗像素复原(Adversarial Pixel Restoration)自监督任务,用少量无标签样本训练替代模型。本文提出的min-max目标函数可以找到一个更鲁棒更平坦的最小值,提高对抗迁移性。
本文3点贡献:1. 提出了一种自监督对抗像素恢复方法,通过在平坦损失表面上学习来找到高度可转移的模式。我们的训练方法允许在不访问大规模标记数据或预训练模型的情况下实现cross-domain 攻击。2. 对抗攻击方法是自监督的,和任务无关。所提方法生成的扰动可以迁移到不同任务中。3. 本文方法使损失更平滑,有助于生成更通用的对抗样本。当训练集仅包含两个样本时方法依然有效。
方法
给定一个无标签的数据分布\(p_s\),样本数量\(\leq 20\),由于数据都是无标签的,可以定义一个自监督学习任务\(\mathcal{T}_s\)训练替代模型,一个主要的挑战是,深度神经网络可以很容易地记忆数据,即使使用较强的数据增广方法,模型还是会快速过拟合少数可用的样本。这导致替代模型的可泛化性较差,因此,从该模型生成的对抗攻击具有较弱的可转移性。
Adversarial Training via Denoising 本文提出一个min-max训练过程,max过程通过单步攻击的对抗像素变换欺骗模型\(\mathcal{F}\),min过程去噪并恢复特征和像素空间,实现可泛化的损失面。
对抗像素变换 对于输入\(x \sim P_s\),通过下面目标寻找满足\(\Vert x-x^{\prime}\Vert_{\infty} \leq \varepsilon\)对抗样本\(x^{\prime}\), \[ \underset{\boldsymbol{x}^{\prime}}{\operatorname{maximize}} \quad \mathcal{L}_{\max }=\left\|\mathcal{F}\left(\mathcal{T}_s\left(\boldsymbol{x}^{\prime}\right)\right)-\boldsymbol{x}\right\|^p \tag{1} \] \(\mathcal{T}_s\)代表像素变换,例如rotation或者jigsaw shuffle,因此,我们的攻击通过最大化式5中所示的损失来欺骗模型恢复转换像素空间的能力,并最终帮助鲁棒自监督特征。上述攻击方法扩展到有监督的情况: \[ \underset{\boldsymbol{x}^{\prime}}{\operatorname{maximize}} \sum_{c=1}^C\left(y_c\left\|\mathcal{F}\left(\mathcal{T}_s\left(\boldsymbol{x}^{\prime}\right)\right)-\boldsymbol{x}^{(c)}\right\|^p\right) \tag{2} \] 其中\(C\)是类别数,\(y_c\)是one-hot标签,\(x^{(c)}\)是选取的特定类别原型。
像素重建 对于公式1生成的对抗样本\(x^{\prime}\),最小化原始图像\(x\)和模型对抗变换输出以及原始样本变换输出之间的重建错误: \[ \mathcal{L}_{\text {out }}=\left\|\mathcal{F}\left(\mathcal{T}_s\left(\boldsymbol{x}^{\prime}\right)\right)-\boldsymbol{x}\right\|^p+\left\|\mathcal{F}\left(\mathcal{T}_s(\boldsymbol{x})\right)-\boldsymbol{x}\right\|^p \tag{3} \] 在对抗训练中,我们进一步调节模型的特征空间,通过强制原始和对抗特征分布之间的对齐,如下所示: \[ \mathcal{L}_{\text {feature }}=\left\|\mathcal{F}^n\left(\mathcal{T}_s\left(\boldsymbol{x}^{\prime}\right)\right)-\mathcal{F}^n\left(\mathcal{T}_s(\boldsymbol{x})\right)\right\|^p \tag{4} \] 其中\(\mathcal{F}^n\)代表encoder中间层输出,整个训练目标: \[ \mathcal{L}_{\text {min }}=\mathcal{L}_{\text {out }}+\lambda \mathcal{L}_{\text {feature }} \tag{5} \] 训练过程伪代码:

实验
本文考虑\(x_{\infty}\)对抗攻击,扰动边界\(\varepsilon \leq 0.1\),考虑in-domian和cross-domain数据,adam优化器学习率0.001,\(\delta=\frac{2}{255},\lambda=1,p=2\)。
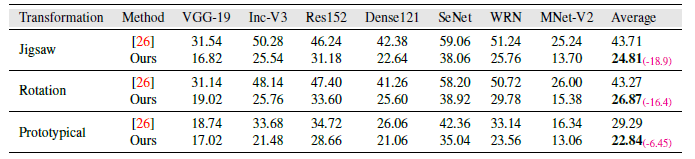
Surrogate Training with Few Samples: 使用公式1作为无监督对抗像素变换(\(\mathcal{T}\)),公式2针对有标签,使用多个decoder的模型。
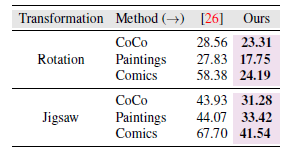
Surrogate Training with Large Dataset: 在paintings(79K 样本),CoCo(40K 样本),和Comics(50K 样本)训练替代模型,测试本文所提方法的cross-domain对抗迁移性。
目标模型: VGG-19,Inc-V3,Res152,Dense161,SeNet,WRN,MNet-V2,ViT-S,DeiT-T 和DeiT-S,鲁棒ResNet-50,DETR 和DINO评估跨任务迁移性。
数据集:在5K 来自ImageNet Val样本测试分类模型,目标检测CoCo(5K)视频分割DAVIS (2K)
Baseline 对抗攻击:200 iterations I-FGSM,100 iterations of ILA,攻击目标:公式1
in-domain
cross-domain:在所有CNNs上求平均的结果
消融实验结果省略......
Practical No-box Adversarial Attacks with Training-free Hybrid Image Transformation
还未正式发表
动机
针对no-box提出一种不需要训练的方法,在分类任务中低层网络提取到的特征的高频部分(HFC)至关重要,如果一个扰动可以有效地控制图像的HFC,模型将会提取完全不同的底层特征,导致模型错分。[2]表明对抗扰动的有效性在于它包含不相关的特征,这些扰动的特征在原始图像特征中占主导地位,文本设计包含不相关特征的的对抗HFC,本文发现有效噪声HFC是区域均匀,重复密集的。
方法
本文猜测有效的扰动应该是均匀重复密集的,采用混合图像(hybrid image [1])的思想,提出一种 Hybrid Image Transformation (HIT) 攻击方法。hybrid image:将一张图像的HFC替换为另一张精心挑选的图像的HFC,并用两种不同的解释制作混合图像:一种是在近距离观看图像时出现的,另一种是从远处出现的。HIT 减少了原始的HFC,同时增加了精心设计的噪声HFC来攻击dnn。
具体实现就是生成由下面三种图案均匀排列的patch \(x^p\),这个patch的大小和要攻击的图像相同,一个图案包括几个形状定义为密集度
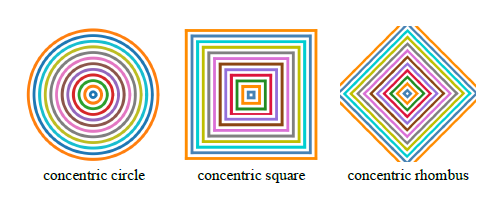
然后定义一个高斯低通滤波器\(G\),大小是(\(4k+1 \times 4k+1\) ),定义为: \[ G_{i,j}=\frac{1}{2\pi \sigma^2}e^{-(\frac{i^2+j^2}{2\sigma^2})} \tag{1} \] \(\sigma\)越大,更多的HFC将被过滤掉,用原始图像的低频部分和patch的高频部分融合生成对抗样本: \[ x^{a d v}=\operatorname{clip}_{x, \varepsilon}\left(x * G+\lambda \cdot\left(x^p-x^p * G\right)\right) \tag{2} \] 从下图可以直观的看到,黄框框出来的box,HIT减小相关的HFC并且添加了不相关的噪声,目标模型无法提取正确的特征来做出合理的预测,从而导致分类错误

实验
实验部分考虑了ImageNet和三个DCL 框架[3]下细粒度分类CUB-200-2011,Stanford Cars 和 FGVC Aircraft,由圆组成的patch攻击效果更好,实验结果和消融实验具体看原本,这里就不放了
总结
这两篇工作考虑了实际中训练替代模型和目标模型的数据分布不一致,且仅有少量训练数据(有标签/无标签)可用是如何训练替代模型。但是在实验设定上用20个样本训练一个替代模型,攻击5000个样本需要训练250个替代模型,在实验设置上并没有对比用5000个样本训练一个模型的迁移效果。在第一篇中Beyonder作为替代模型测试IFGSM对5000样本攻击迁移效果,其他方法都是IFGSM+ILA,对于不太公平。IFGSM和ILA攻击收敛慢,在文章中分别要迭代200和100步,减少迭代次数达不到最佳效果。
在第三个方法中,HIT用在某些中间层feature上效果如何还可进一步研究。图案的选取没有什么依据,在文章中对比了三种最常见的形状,对抗样本的生成不需要训练,也不需要迭代,从这一点来看是一种非深度学习的方法。